淘宝买家订单导出
文章目录
最近想分析一下2018年10月第一次入了伟力的12428小车以后在模型上的消费,但是从2018年到今年很多的订单。本想自己截图一下然后计算的,但发现非常的麻烦。淘宝又没有工具能够导出订单的工具。手工做的话还是放弃吧,还是研究下自动的方式。
使用selenium等方式还比较麻烦,试了下无法登陆,拖动验证码的时候就报错了。打开API请求发现翻页的API请求asyncBrought包含了订单的详细信息,非常的方便。
怎么拦截这些API请求呢?想用下Tempermonkey但似乎没提供拦截的功能。还是用一个中间代理mitmproxy这个工具能够满足这样的需求。 代码很简单,只需要把asyncBought拦截,然后把数据写到一个json文件即可。json文件用当前的页码作为文件名,比较好处理。
import json
from mitmproxy import ctx
import arrow
def response(flow):
response = flow.response
if 'asyncBought' in str(flow.request.path):
resp = json.loads(response.text)
print(resp)
with open(f"./out/{resp['page']['currentPage']}.json", "wt", encoding='utf-8') as f:
f.write(response.text)
运行mitmdump -s 执行这个脚本,遇到了Chrome的HTST的报错。参考这里关闭这个功能:https://appuals.com/how-to-clear-or-disable-hsts-for-chrome-firefox-and-internet-explorer/
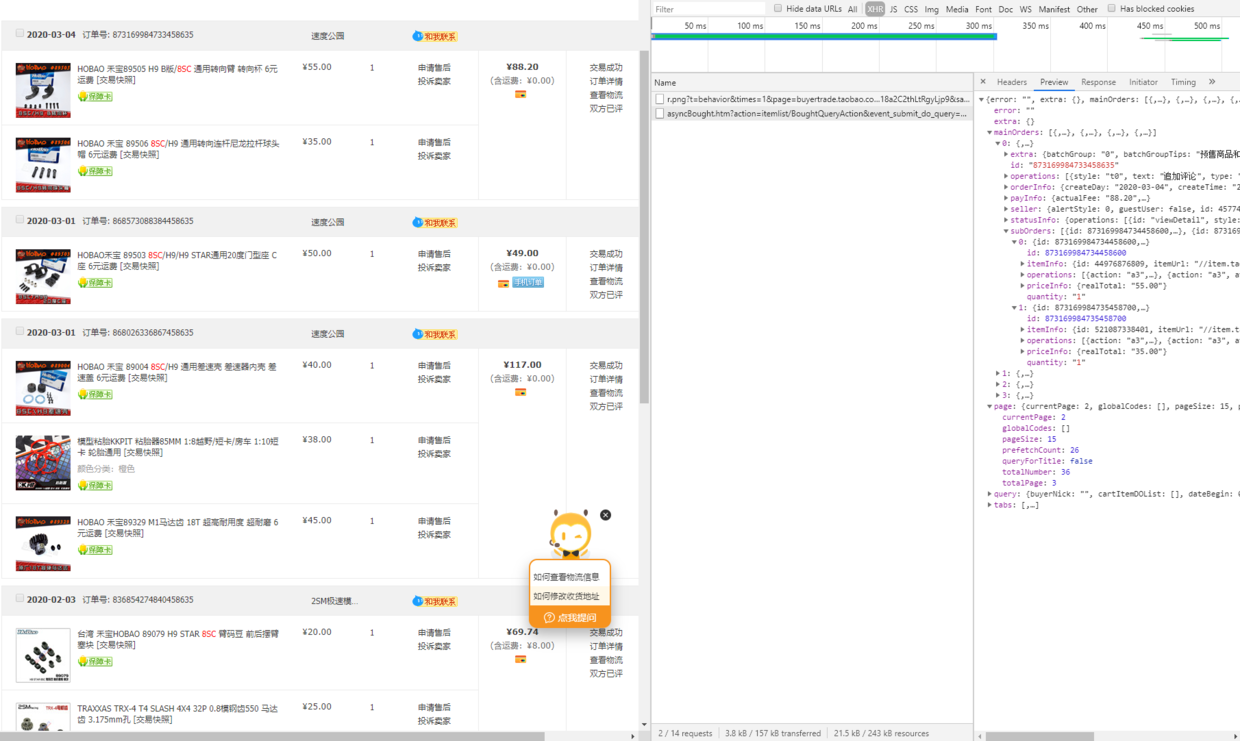
弄好了以后,只需要手工点击“下一页”数次即可抓到所有的数据:
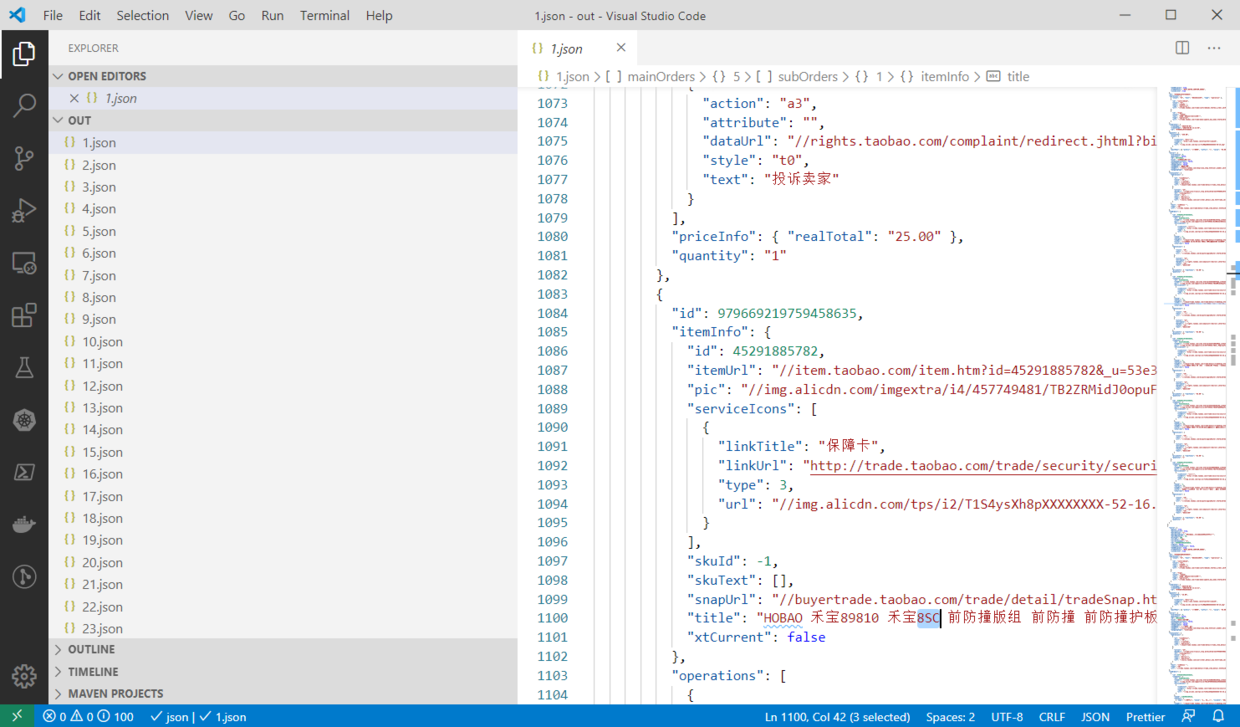
拿到这些数据后,在写一个脚本,将json读出来,提取出有用的信息,放到csv里面即可。
import glob
import json
import csv
with open("order.csv", "w", encoding='utf-8', ) as order_csv:
writer = csv.writer(order_csv,lineterminator="\n")
for file in sorted(glob.glob("./out/*.json")):
with open(file, "rt", encoding="utf-8") as f:
j = json.load(f)
for main_order in j['mainOrders']:
if main_order['statusInfo']['text'] != '交易关闭':
for sub_order in main_order['subOrders']:
skuText = ""
if 'skuText' in sub_order['itemInfo']:
for item in sub_order['itemInfo']['skuText']:
skuText += item['value']
writer.writerow([main_order['orderInfo']['createDay'],sub_order['itemInfo']['title'], sub_order['priceInfo']['realTotal'],skuText])
这样一个csv就可以导出了,后续就可以用excel来处理了。添加上一些额外的列帮助分类即可。
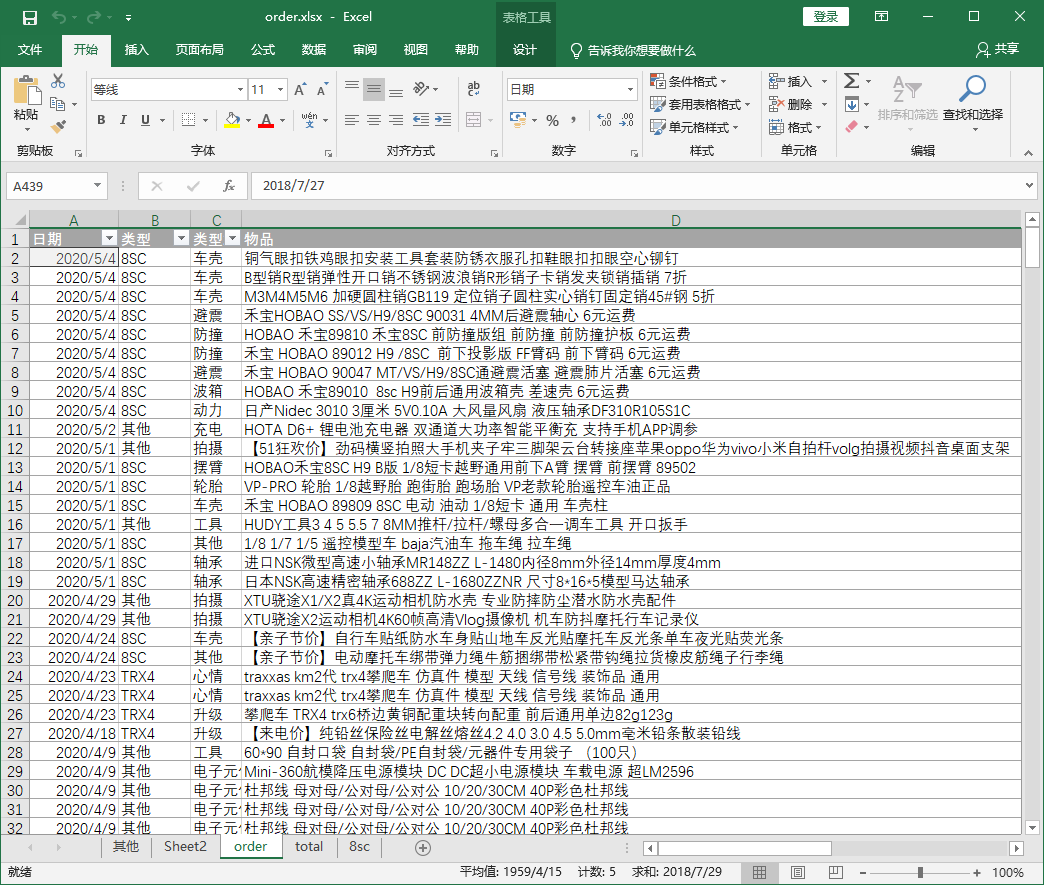
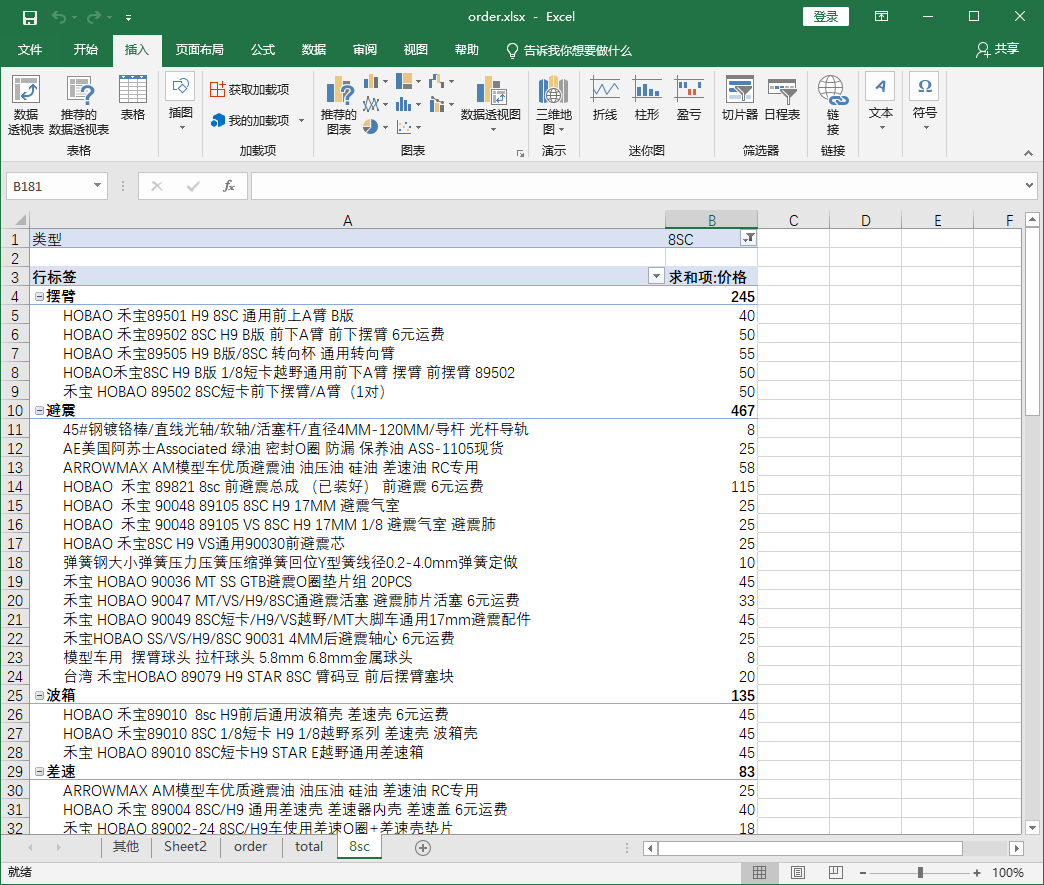
建立数据透视表进行分类总和:

总结下来用自动化的方式链接API请求,非常的方便,节约了大量的时间。
文章作者 贺思聪
上次更新 2020-05-05
许可协议 未经原作者许可禁止转载