从数据到产品——爱飞狗背后的故事
文章目录
这篇文章基于最近整理的一份演讲的Slide,由于报名太晚错过了截止日期,所以只好写成文章,一起来看看爱飞狗背后的一些故事。

几年前我和家人会经常往返于成都和广州两个城市,从平时的观察中可以看到机票价格从400人民币到全价接近1500人民币,机票产生的波动有时候会高达100元以上,如果没有看好时间,一家人出行就会增加几百元的成本。

买机票的时候,我应该和大家差不多,会在买机票前进行一番观察。主要是观察未来几天起飞的机票价格,用来选择哪天出行。然后手工记录一下近期的价格变化,看看是不是在涨价还是跌价中。当然这个纯属体力活也容易错过最佳购票时期。我当时在想,如果我能知道去年的机票的价格和变化趋势,或许可以用来预测今年的价格的波动和判断是否需要购买机票。

我提出了两个问题,近期的价格的趋势是什么?决定好起飞时间后,我应该提前多少天购票?

我查了一下目前我们有的一些服务和APP,看是不是有人已经做过了类似的事情。
- Farecast是最早做机票预测服务的一家公司,后来被微软收购后并入了Bing,此后Google收购了Farecast所依赖的数据源后,Bing的这项业务也停止了,所以现在Farecast已经关闭,无法使用。
- Kaya这家网站提供了机票的近期价格曲线以及购票建议,十分切合我的需要,但遗憾的是中国的数据源非常少,几乎没有可参考性。
- Hopper也是最近两三年比较好的一款App,提供了出行的建议以及是否购票的提示。但Hopper不会提供去年的曲线图,也没有近期的票价情况,一切看你是否相信它的AI预测了。和Kaya类似,这个App也没有中国区域足够的数据,没有什么参考价值。

面对这样的情况,作为一个程序员,我觉得是时候出手了。

由于我没有运营机票代理业务,所以无法获得机票信息的一手资源。对于我来讲唯一能够获取到数据的方式就是采用爬虫,通过模拟人工的搜索来获得票价信息,存储到数据库中。

为了分析一整年的数据,我在给自己定了一些目标:
- 至少要连续采集1年的数据
- 更新频率大概在1小时左右
- 低成本
- 容忍爬虫或者数据源的失败

根据这些目标结合当时的情况,我将这个任务分解成了以下几个部分:
- 机票采集的范围:中国范围内2800个航线的直飞的价格数据
- 采集的数据:每条航线起飞前45天的票价信息
- 数据源:4个数据源做互补,一来是为了检查数据的准确性,二来是为了防止数据源失效
- 全年无休连续爬取
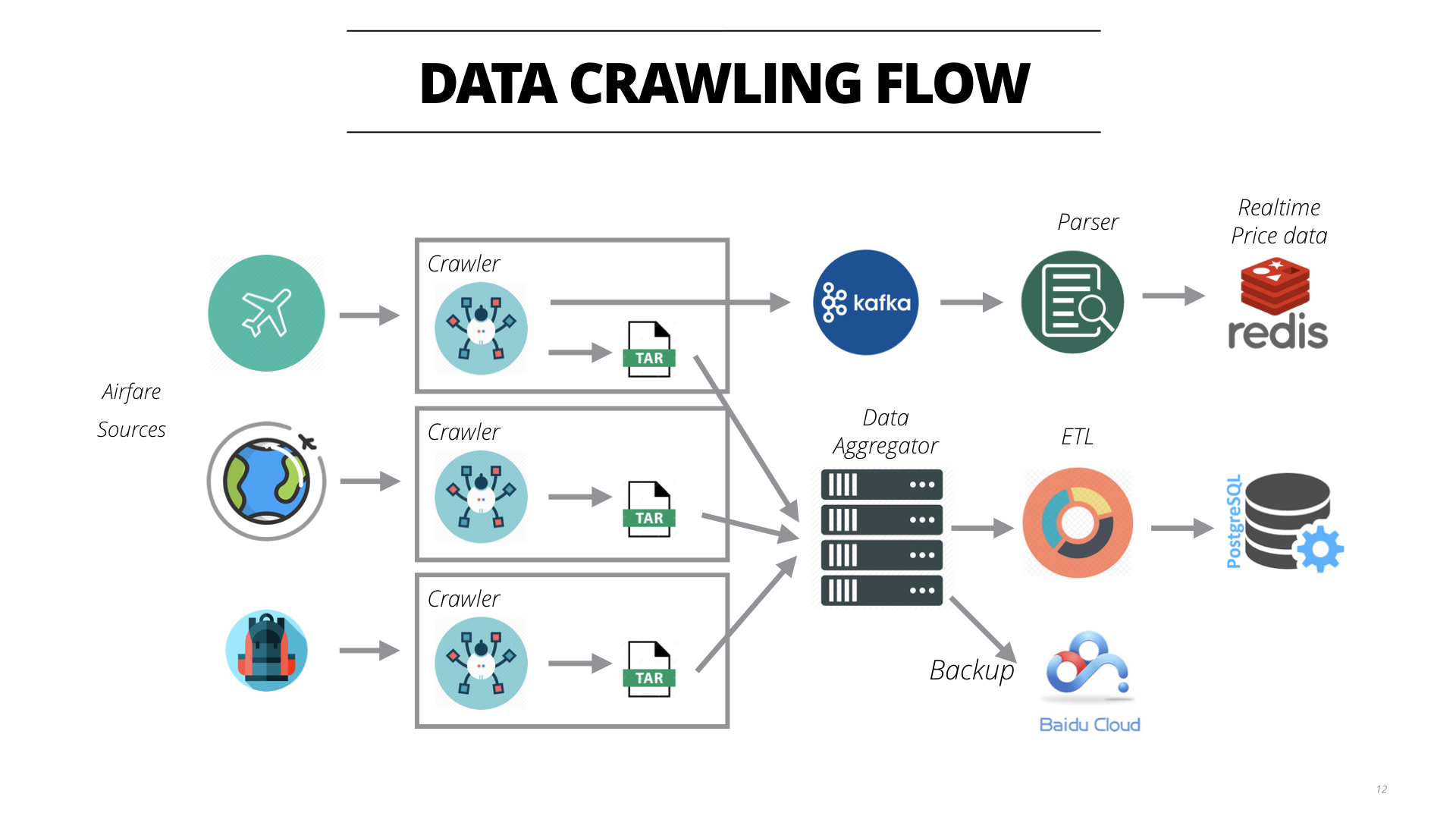
在数据爬虫的架构上,我需要一个低成本的方案,毕竟要干上一年以上的时间(其实到现在已经2年多了)。我并没有使用各种爬虫的框架,而是自己写了一个轻量级的爬虫来处理代理的筛选逻辑和爬取数据的验证。这些爬虫将会运行在DigitalOcean或者Linode的$5的服务器上,这些服务器上只有1个CPU和1G的内存。自定义的爬虫能够尽可能的根据性能进行针对性的调优,从而增加性能。每个爬虫之间互相独立,部署在单独的机器上,也是为了减少爬虫之间的相互干扰。
在存储上我是用了tar.xz的文件将所有的爬取到的原始文件按照每一轮爬取进行打包压缩,然后在本地里面的一台PC机负责将所有的数据拉回来,放到一个4T的硬盘上。同时这些数据也会存储到百度云上面进行备份。目前这些压缩包已经达到2T左右了,解压下来大约有20T的数据量,大约有380亿条数据。
在数据处理上,首先是实时数据流的处理。使用了kafka来进行队列管理,一个Parser来进行实时的处理原始数据,将处理好的结果放到redis缓存中,供小程序的后端使用。
在数据的分析上,我使用Java手写了一个高性能的ETL,直接读取压缩包然后进行数据解析。在这里也是使用了轻量的原则,没有使用更多框架,从而达到非常高的性能。
在PC机上也使用了Postgres中进行数据存储,每一天的数据存储到一个表中。
在近两年的时间中我积累了以下一些经验:
- 在长时间的爬取中证明了简单的爬虫的可变性非常好,在针对特殊场景调优的时候非常有针对性。
- 存储原始文本也为了应对数据结构的变化,当数据结构变化后,本地的Parser失败以后,可以重复的调用之前的数据,从而保证数据不丢失。
- 多个数据源进行备份的设计非常好。目前依然有两个数据源在持续爬取。针对两个数据源我也可以进行数据的对比,发现数据对比后数据较为相似,说明没有爬取到脏数据。

拿到这些数据后,就要开始数据分析了。

分析的结论在我的简书的前几篇文章中都有提到。这里不再赘述,请参看: https://www.jianshu.com/p/3b22fb101189 https://www.jianshu.com/p/366e839af3ea
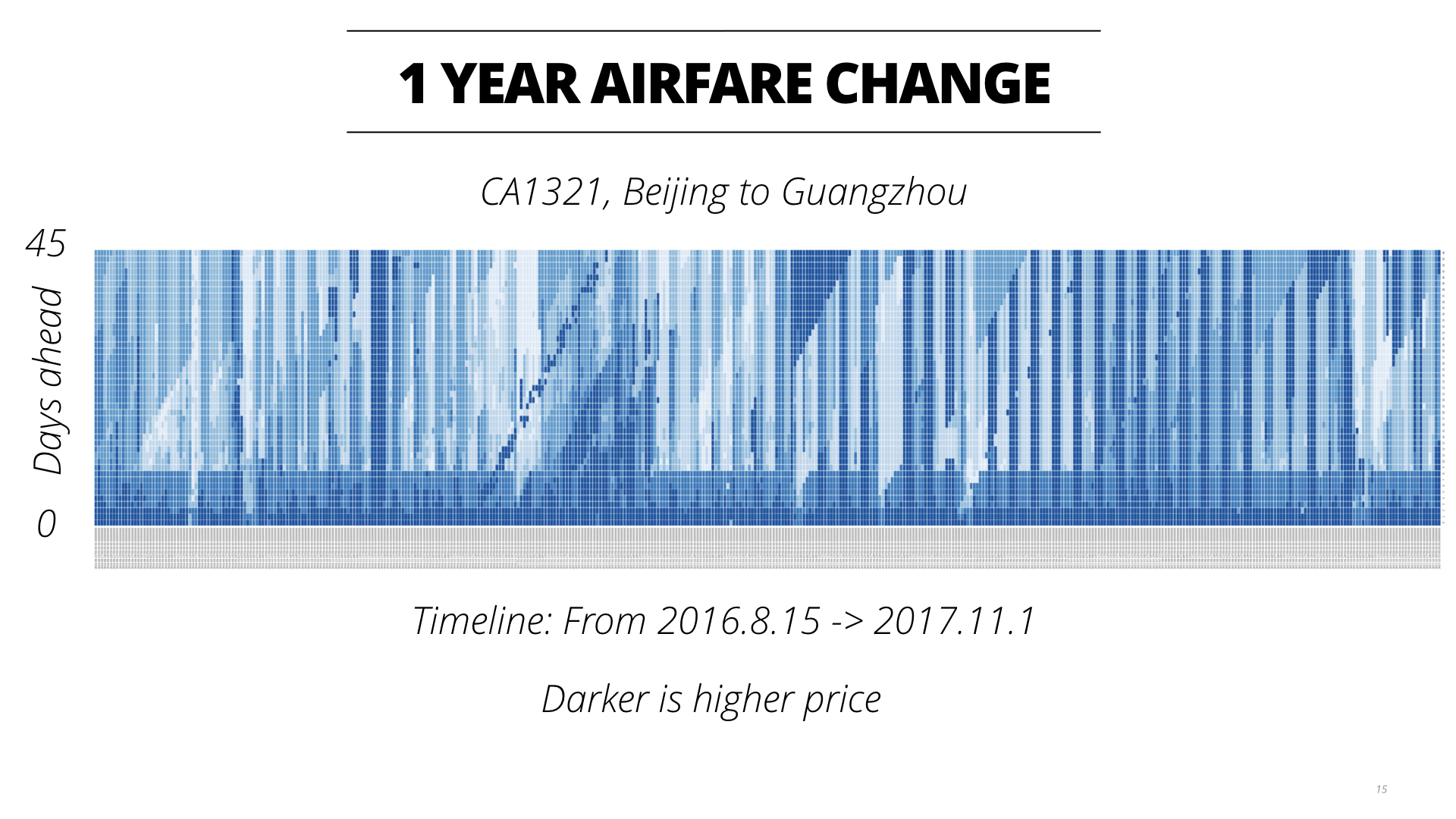
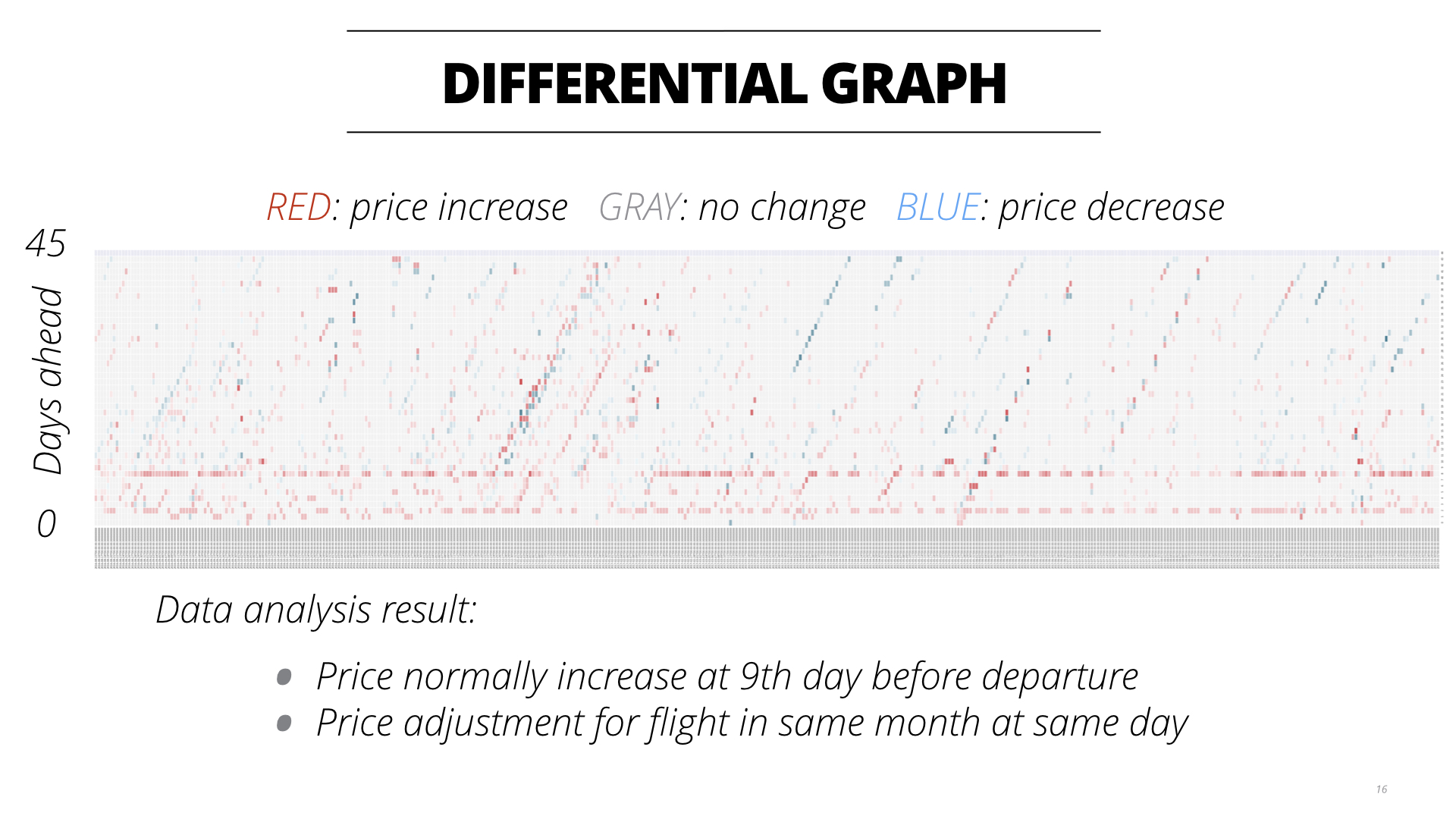




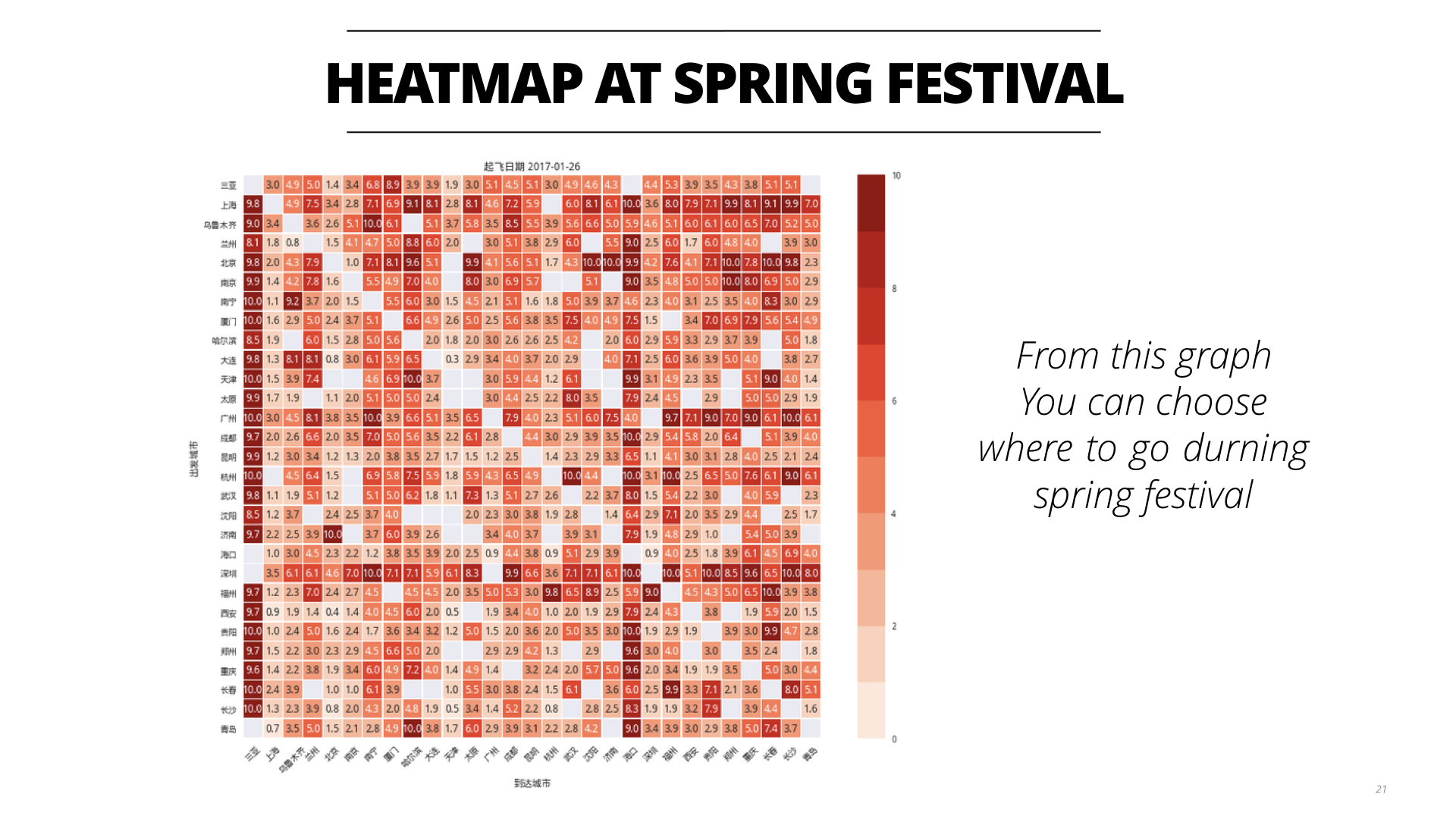
在分析完这些数据后,我们再回头看一下最初问题的定义:针对某一条航线,给定历史价格和近期的价格,现在看到当前的价格是P和距离起飞还有N天,我们应该是买还是等待?

我使用了以下一些算法来分析,包括决策树、支持向量机、Q-learning和神经网络。
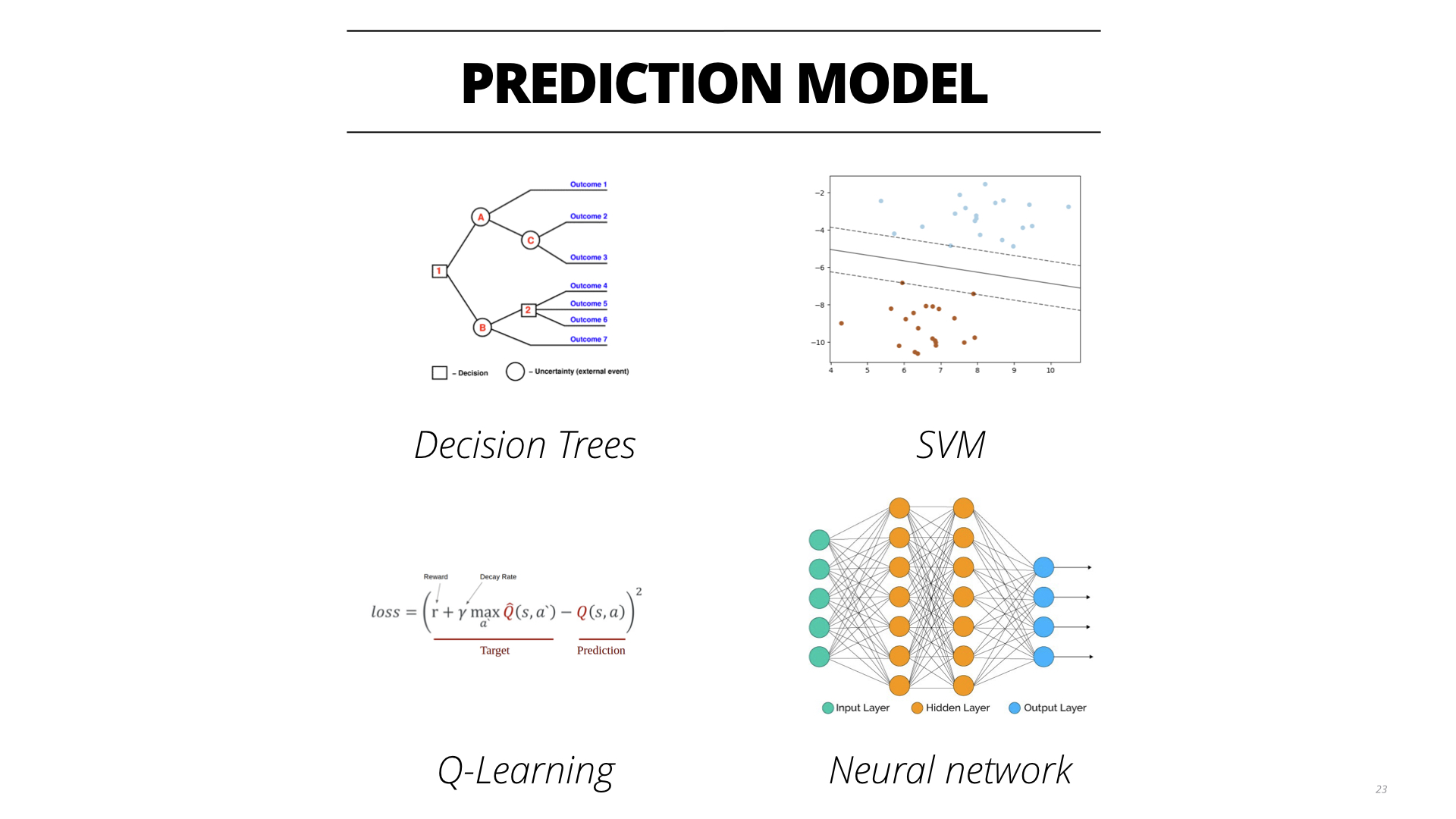
在准备数据时,提取了以下一些基本特征,当然针对不同的算法还是用不同的特征。

在数据的分割上,考虑到这个是时间序列相关的数据,将数据集分为1年的训练数据,2个月的测试数据和2个月的验证数据集。当然实际数据比这个多,可以尝试更多的组合。

但这些算法算出来的结果还并不令人特别满意,达到的准确率也只能超过人工根据一些简单的规则推导出来的准确率,可能和我所用的数据训练方式有关。所以在线上计算的时候,我目前还是采用专家系统的做法,将数据分析的结果整理成规则,根据这些规则还是能够得到较高的预测准确率,其他的指标例如Recall等可能会比较差。

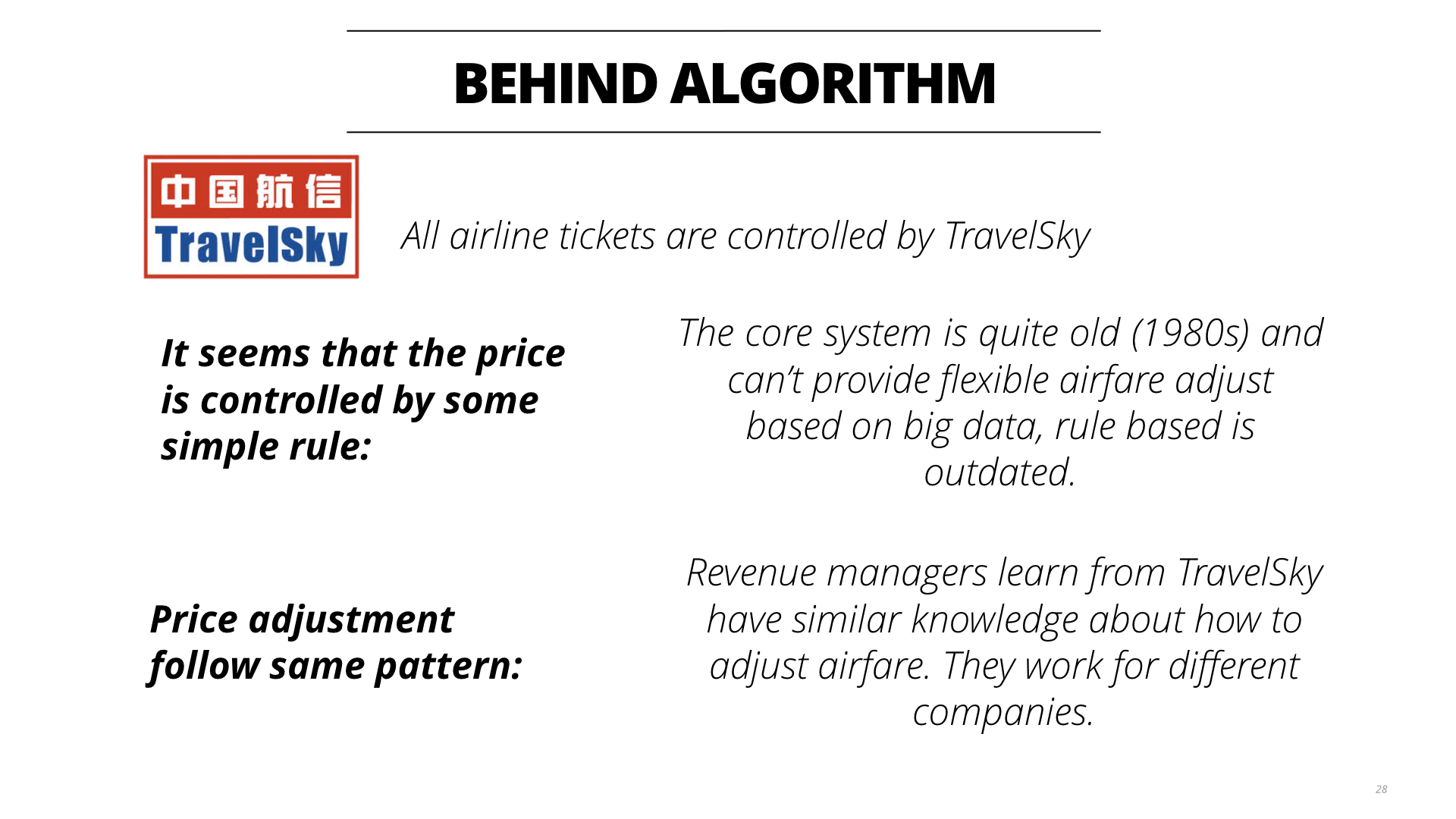
那么为什么专家系统能够行得通呢?我从一些内部人士了解到,原因在于这些机票都是来源于中航信,而这个系统比较老旧,针对价格的调整也不够灵活,大多数都是给予一些人工的规则来进行。收益管理员基本上都是从这里学到一些规则然后进行调价,所以学到的规则其实比较相近,所以会产生大家都有差不多一样的规则。
有了数据之后,想到可以来造福大众,便产生了做一个小产品的想法。

这时候正直小程序比较火的年代,小程序比较简单,而且受益于微信的用户群可以很方便的进行推广。所以设计了几个简单的功能,能够选择出发、到达和起飞日期,然后会显示出实时的价格和历史最低的价格,点进去后可以看到预测、近期的价格波动和去年的价格波动。这能够更好的指导大家进行机票的选择。

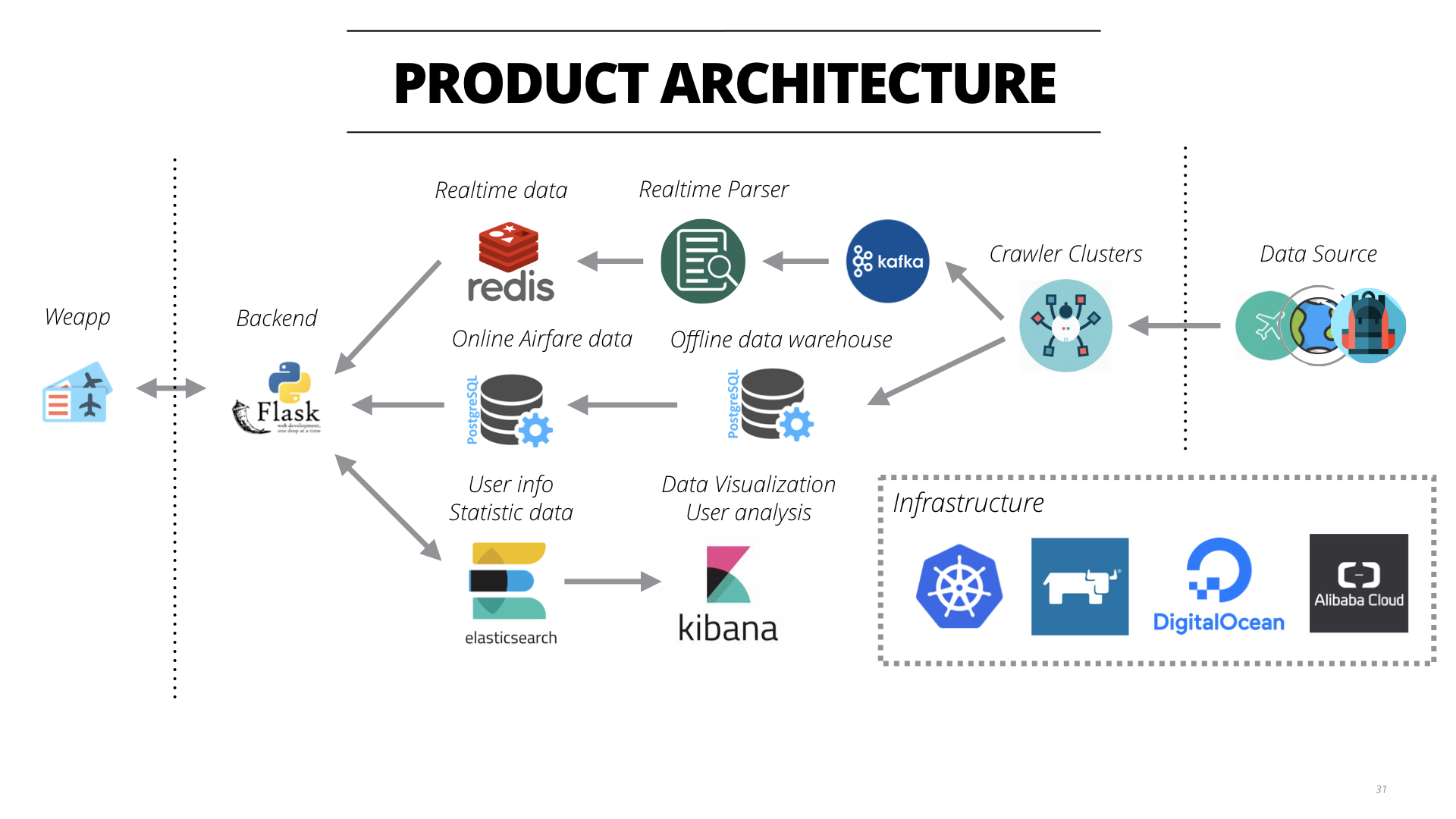
下面来看看产品背后的架构:
- 前端当然是用微信提供的一套进行开发,这个和其他的小程序没有什么两样。
- 后端使用Flask进行开发,简单快捷。
- 数据提供方面有之前提到的实时数据的显示,来自Redis缓存,当然还有离线历史数据数据。这些数据每天从离线的PC机上同步到云端,然后由API进行展示。
- 还有用户行为数据的存储及分析。这些数据都存在ElasticSearch服务器中以便进行快速的搜索,借助Kibana可以对用户行为进行在线的分析,非常的方便。当然还有一些和用户相关的需要实时更新的数据(例如session值和飞币的信息)也放在EleasticSearch中,主要是利用了NoSQL数据库没有Schema的特点,增加数据使用的灵活性。
- 基础设施方面小程序相关的部分全部在阿里云的服务器上。所有的服务都使用Kubernetes进行管理,Rancher进行可视化管理,爬虫等服务放在DigitalOcean一遍节约成本。
小程序也发布了9个多月了,目前积累了大约4.3万的用户,数量还相对较少,这个小程序的未来如何考虑呢?

首先是继续将机器学习应用到价格的预测,毕竟积累了2年的多的数据是一笔不小的财富。 然后是提供更好用的界面提升用户的使用满意度。 最后就是找到一套可行的商业模式进行变现。目前小程序还只能依靠广告有一点收益,完全是入不敷出的情况。
如果您对这个小程序感兴趣,请试试微信搜索“爱飞狗旅行”和关注微信公众号“爱飞狗”,或者扫一扫下面的二维码。您的支持将是我进步的最大的动力。

文章作者 贺思聪
上次更新 2018-07-25
许可协议 未经原作者许可禁止转载