小心!我正在偷窥你的运营
文章目录
首先,问一个很简单的问题考考你——在上海,摩拜单车出行的高峰时段是什么?这个问题相对比较容易回答,根据普通人上下班的时段应该是早上七八点左右,下午六七点左右。恭喜,你答对了。
现在问一个稍微更难一点的问题:在上海,摩拜单车使用次数的分布是什么情况?对于我而言,基本上每天就从地铁站骑到公司,然后下班从地铁站骑回公司,就算做是两次吧,通常这部分人应该不少。而这道题问的是分布,那么得知道0次骑行的车的数量,骑行一次、两次、n次的车的数量。我们可以做个小范围的采样,在单车密集的区域架设几个摄像机,然后分析一下哪些车没有被骑走即可。但是,骑行两次、三次以及更多次数的车的数量如何得知呢?我们很难知道,或许我们可以通过发放调查问卷来得知,但如果样本太少会得到打的偏差。同样的道理,回答“摩拜单车的骑行距离的分布式什么情况”,也相对较难。
要知道共享单车的运营情况,我们通常只能通过官方或者研究机构的各种报告来获取到。然而这些报告可能缺少一些时效性,对某些研究来讲并不能产生任何作用:例如在城市规划时研究OD线、叠加图层分析更多因素的结合时,就显得无能为力。最后的渠道也是最正规的渠道是通过和共享单车企业合作,然而由于涉及到商业机密,通常很难获得。
OD线(Origin-Destination Line),是指连接“起点”(origin)和“终点”(destination)的线,通常用于在地图上直观表示某两个地理位置之间的联系,如车辆的行驶轨迹、飞机的航线和人口的迁徙等。
回到单车的APP上来,既然能够帮我们显示出车辆的信息,那么我们能不能把一个区域的范围的车的信息都抓取下来,然后进行分析呢?这个思路非常的有趣,在我之前写的摩拜单车爬虫解析——找到API 中已经有所涉及。在这里我们不谈技术细节,通过对爬取的上海市2018年5月29日星期二(晴天)的数据进行分析我们迅速地得出上面问题的答案:
- 单车的分布图和部分热力图。可以明显的看到上海城市的发展规模以及人口密集区域的分布。
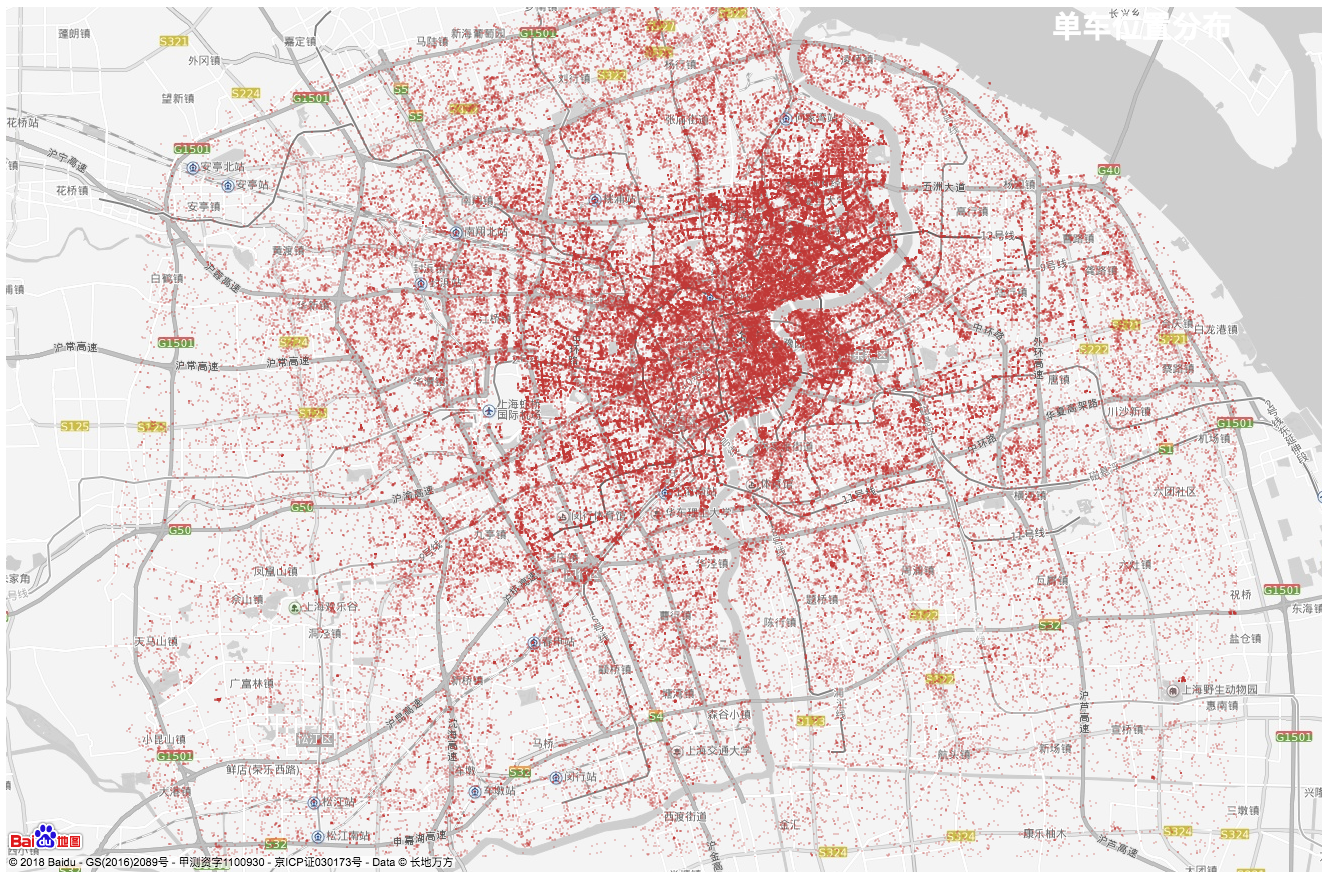
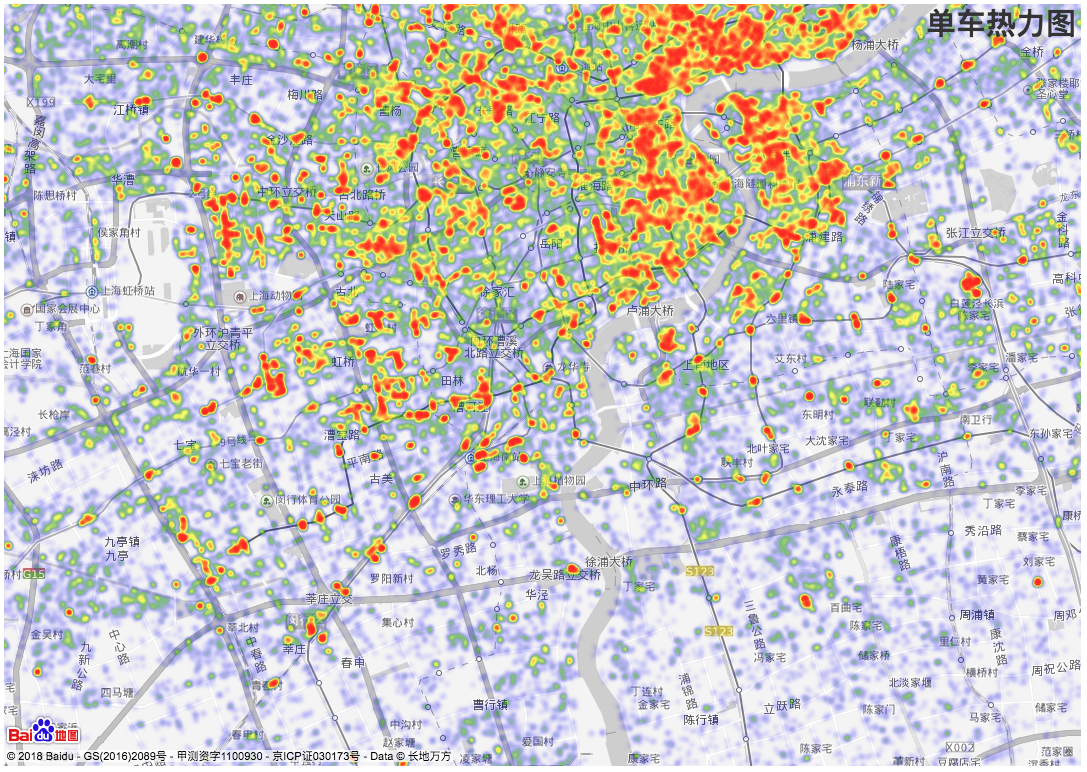
-
单车使用次数类似一个正则分布,2次的次数最多,符合人们的直觉。
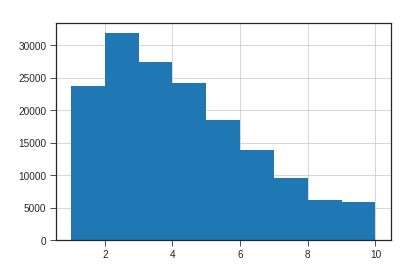
-
骑行的直线距离分布在2千米之类,以1千米范围为最多,这通常也是单车解决“最后一公里”问题的证据。
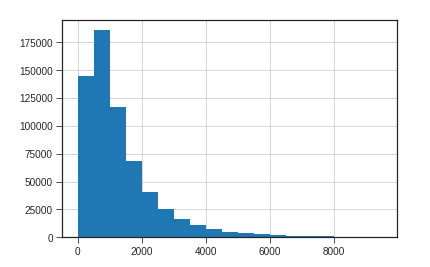
-
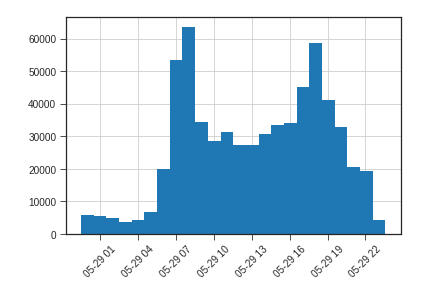
出行的时段的分布在早上7点左右达到高峰,然后晚上7点左右达到高峰,这和人们的出行习惯是密切相符的。有趣的是夜间22点以后到第二天凌晨5点左右,也有单车在移动,但这时候骑行的人相对很少,所以这些单车的移动很有可能是摩拜单车的运营人员在批量的挪单车。如果将这些数据加以分析应该可以知道这些车从哪里挪到哪里,进而更深层的分析单车企业的运营策略。
同样的道理,让我们来看看共享汽车的运营情况。我们抓取了去年GoFun从10月到1月的数据,得出了以下一些运营状况的分析:
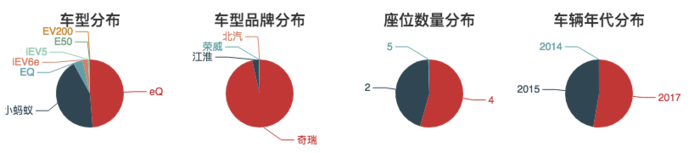
- GoFun绝大多数车型都是奇瑞的车。两座和四座的车是主流,车身小巧一方面比较节能,另一方面比较容易操作。这主要是因为奇瑞投资了GoFun。
- 截止2018年1月26日,GoFun目前在全国总共有10327辆车。下图是车辆增长的情况。可见运营一直在持续,并且缓慢增长。

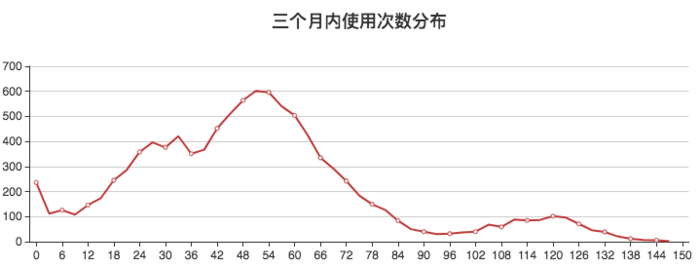
- 三个月内车的使用次数的分布。横坐标是使用的次数,纵坐标是次数对应的车的数量。近似一个正态分布,大约70%的车都在24到72的区间。平均起来每天0.3次到1次左右,这对于共享汽车企业来讲并不是一个好事,太低的使用率可能会导致入不敷出。
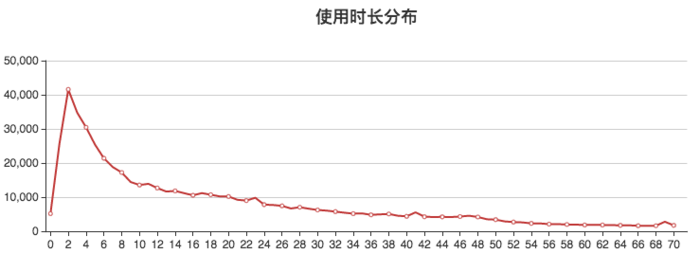
- 使用时长的分布。横坐标代表停车的时长(小时)最长统计到70小时,纵坐标代表有多少车次。对比停车时长的分布,使用时长的分布比较明显的集中在0到6小时之间,这也是共享出行的特点。由于GoFun有包天的租车服务,所以长期的出行的费用也是可以接受,长达70小时以上的使用时间也有1700多车次。
由于篇幅所限,更多的分析结果可以参见大数据看共享汽车一文。
保护我们的数据
以共享单车为例,当我们手工的小范围的采集数据时,并不能产生很大的作用,当我们收集到的数据越来越多时,甚至通过自动化爬虫这种手段获取到足够多的数据以后,大数据就开始展现量变到质变的过程。共享单车、共享汽车的案例中,虽然我们没有得到订单的数据、没有用户信息,但通过对海量数据分析、结合多种维度,我们依然可以窥探企业的运营。我在2017自由职业大数据分析一文中爬取到Freelancer网站的所有公开信息并进行了自由职业的分析;在机票大数据分析,揭示购票的秘密 中,通过一年多的机票价格数据采集得到多个机票购票的建议。所有的数据都来自于公开的API,而主要的获取方式则是爬虫。
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
爬虫获取信息的方式可以通过爬取页面,也可以通过分析APP的请求来得到API。所以一切返回数据的地方都是可以通过一些手段获取到,而主要的区别在于获取数据的难度的大小,这也通常是爬虫和反爬虫的较量之一。当爬虫的成本高到一定水平以后,反爬虫就胜利了。
通常来讲,反爬虫的手段无外乎对IP限制、验证码、要求登录等,可以参考关于反爬虫,看这一篇就够了一文。固然这些方式都可以较好的保护应用,但会给适用方带来不便,除此之前我们可以考虑一些建议来减小数据被大规模爬取的可能,增加爬虫的成本:
从业务上进行考虑,不需要客户感知的数据不提供或者少提供
以单车应用来看,ofo单车并没有提供摩拜单车的预定的功能,所以在界面上也没有必要展示出单车的编号信息。在去年9月份左右,ofo单车对API进行了调整,将所有的单车编号进行随机化处理,导致ofo单车的数据目前无法爬取。哈罗单车在未登陆的情况下只提供几台单车的数据,登陆后能够展示附近所有的单车。由于需要登录,爬虫的成本会变得很高也非常的脆弱。 反观某大型旅游OTA网站的API,调用后返回了相当数量的额外信息,甚至在价格方面包含了两种价格,而其中一种价格并不会在界面上进行显示,这种信息非常值得怀疑是不是内部的价格。
盘点所有的API的使用方,谨慎一切以JavsScript开发的客户端
目前手机APP层面的保护措施已经相对较多,而且大多数应用受到加密外壳的保护很难破解,想得到URL里面的签名信息的生成方式变得非常困难。然而仔细盘点一款产品的各种渠道,会发现有些产品可能会提供HTML5、公众号、小程序等入口,而这些以JavsScript生态圈的应用并未收到很好的保护。 以某款快递软件为例,该查询软件中提供了sign信息,基本无法知道如何生成,但在小程序中调用了类似的API并带上了sign信息,通过一个Root的安卓手机可以将小程序解包,分析JavaScript很容易的发现了sign的生成方式。另外某单车软件登陆的签名信息eption也是经过了加密处理,在小程序中也能够发现其生成的方式,马奇诺防线就这样轻松的被越过了。 当然小程序端的防止爬取的方式比较简单,小程序的后端可以通过微信的接口生成动态的token的方式进行用户验证,防止数据泄露。
做好后台的监控
道高一尺魔高一丈,后台API调用的日志和监控手段要重视。对于异常数量的API调用要及时分析出原因减少被利用的可能。
文章作者 贺思聪
上次更新 2018-06-22
许可协议 未经原作者许可禁止转载